


Monocular Facial Performance Capture Via Deep Expression Matching

Abstract
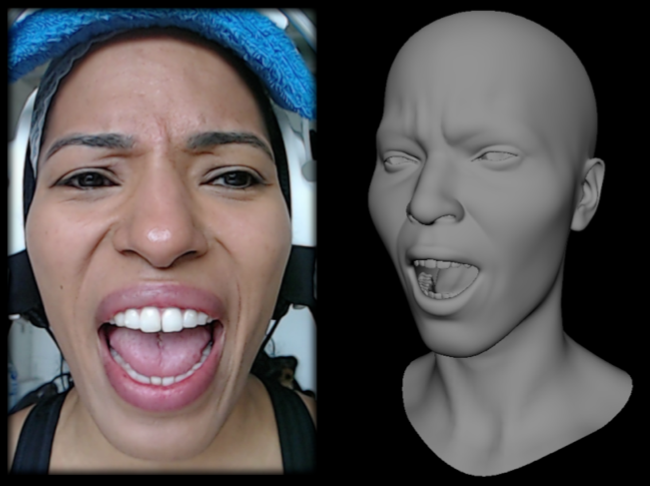
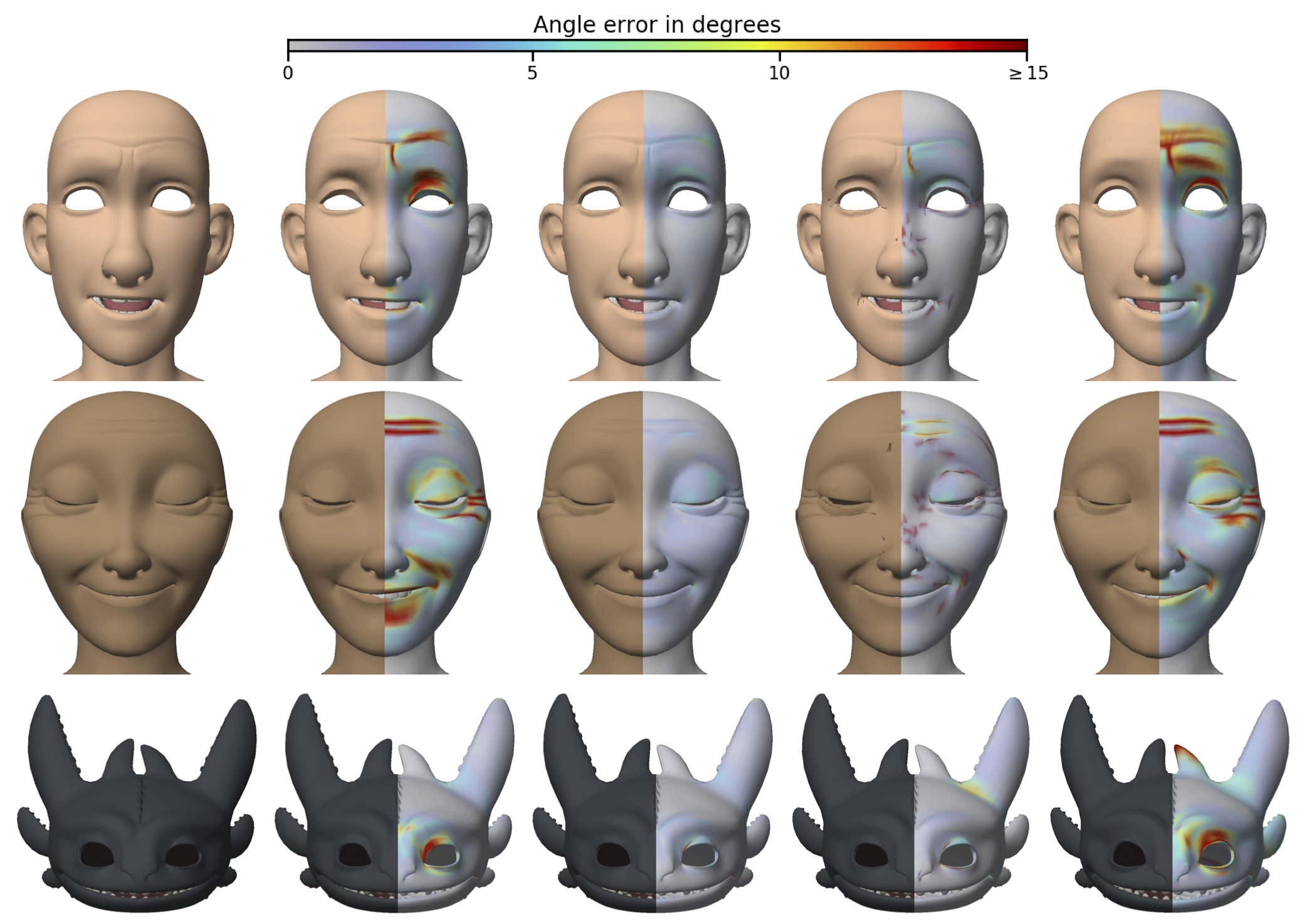
Facial performance capture is the process of automatically animating a digital face according to a captured performance of an actor. Recent developments in this area have focused on high-quality results using expensive head-scanning equipment and camera rigs. These methods produce impressive animations that accurately capture subtle details in an actor’s performance. However, these methods are accessible only to content creators with relatively large budgets. Current methods using inexpensive recording equipment generally produce lower quality output that is unsuitable for many applications. In this paper, we present a facial performance capture method that does not require facial scans and instead animates an artist-created model using standard blend-shapes. Furthermore, our method gives artists high-level control over animations through a workflow similar to existing commercial solutions. Given a recording, our approach matches keyframes of the video with corresponding expressions from an animated library of poses. A Gaussian process model then computes the full animation by interpolating from the set of matched keyframes. Our expression-matching method computes a low-dimensional latent code from an image that represents a facial expression while factoring out the facial identity. Images depicting similar facial expressions are identified by their proximity in the latent space. In our results, we demonstrate the fidelity of our expression-matching method. We also compare animations generated with our approach to animations generated with commercially available software.
Citation
Stephen W. Bailey, Jérémy Riviere, Morten Mikkelsen, and James F. O'Brien. "Monocular Facial Performance Capture Via Deep Expression Matching". Computer Graphics Forum, 41(8):12, September 2022. Presented at ACM SIGGRAPH / Eurographics Symposium on Computer Animation 2022.
Supplemental Material